很常聽到大家討論HDFS的data locality機制,那HBase呢?請看以下連結~
http://dumbointaiwan.blogspot.tw/2012/11/hbase-region-server-and-data-locality.html
2012年11月15日 星期四
HBase Region Server and Data Locality
2012年11月5日 星期一
HTablePool的多執行緒問題
Dumbo in TW是小弟在公司參與的group所維護的blog,往後小弟也會在這邊不定期update Dumbo in TW的更新ㄛ~
http://dumbointaiwan.blogspot.tw/2012/11/htablepool.html
http://dumbointaiwan.blogspot.tw/2012/11/htablepool.html
2012年11月4日 星期日
Hbase系列課程slides之二
今天takeshi要跟大家分享的是HBase系列課程的第二個部分,這部分主要是在講解一般HBase的使用者,透過HBase client API (主要是用Java語言),存取HBase時,有哪些功能可以使用,並且要注意哪些部分,slides如下;另外,課程大綱請參閱Part 1的文章ㄛ~
課程大綱如下~
以上,takeshi今天就分享到這,供大家參考囉 ^^
課程大綱如下~
- HBase Client API的基本使用方式
- HBase Filter API
- HBase Coprocessor
以上,takeshi今天就分享到這,供大家參考囉 ^^
2012年10月23日 星期二
Hbase系列課程slides之一
takeshi很就沒有發佈文章了,takeshi並不是消失了,而是前一陣子換了戰場,一下子有太多咚咚要學,實在是忙不過來ㄚ,其實還是擠得出時間啦,不過都拿去看電影了 XD
前日,遇到以前的同事,他們都在問我blog已經很久沒update了,讓takeshi覺得有一種欠教授作業,很久交不出來,準備被當掉的fuㄚ Orz;所以現在乘takeshi有fu的時候,趕緊擠一篇出來,要不等到下一次有fu,不知是民國幾年了 :p
takeshi最近因公事緣故,準備了HBase的課程教材,主要分為六大部分,依老規矩,先放個心智圖來搏版面 :p
這張心智圖,是從右上至左上,採順時針方向來看ㄛ~
所以本篇文章的重點便是「HBase Introduction」囉~
 服用警語:由於這些slides是takeshi為公司內部使用的,或許其中有一些名詞或連結,是對外無法使用的,
服用警語:由於這些slides是takeshi為公司內部使用的,或許其中有一些名詞或連結,是對外無法使用的,因為takeshi懶得改還請客倌們見諒 Orz
本slides主要在講的是...
從一個Web2.0時代的網站開始講起,由於Web2.0網站的資料,大多由使用者自身貢獻,所以當一個網站越紅的時候,它就越容易遇到儲存資料過量的問題!
儲存資料就用RDBㄚ! 你問十個工程師,大概會有十一人會這樣回答你!那資源有限、任何RDB架構都用上了,最終仍是遇到資料存取速度太慢的問題,你該怎麼辦呢?
大資料時代來臨!!
noSQL及其分類~
主角登場!Apache HBase降臨!!
takeshi google到的一些實務上,使用noSQL架構
以上~~
前日,遇到以前的同事,他們都在問我blog已經很久沒update了,讓takeshi覺得有一種欠教授作業,很久交不出來,準備被當掉的fuㄚ Orz;所以現在乘takeshi有fu的時候,趕緊擠一篇出來,要不等到下一次有fu,不知是民國幾年了 :p
takeshi最近因公事緣故,準備了HBase的課程教材,主要分為六大部分,依老規矩,先放個心智圖來搏版面 :p
 |
| HBase系列課程圖解 |
所以本篇文章的重點便是「HBase Introduction」囉~
本slides主要在講的是...
從一個Web2.0時代的網站開始講起,由於Web2.0網站的資料,大多由使用者自身貢獻,所以當一個網站越紅的時候,它就越容易遇到儲存資料過量的問題!
儲存資料就用RDBㄚ! 你問十個工程師,大概會有十一人會這樣回答你!那資源有限、任何RDB架構都用上了,最終仍是遇到資料存取速度太慢的問題,你該怎麼辦呢?
大資料時代來臨!!
noSQL及其分類~
主角登場!Apache HBase降臨!!
takeshi google到的一些實務上,使用noSQL架構
以上~~
2012年4月6日 星期五
軟體專案的素質之四 ─ 整體設計之 架構設計案例
假設我們作了一個線上書店的網站,因為需要符合客戶快速進入市場的需求,所以在一開始的系統架構設計是採取相當簡單且常見的Three-tier設計,以Tiers & Layers diagram來說,將會是以下內容
 |
| 常見的Three-tiers架構設計,以Tiers & Layers diagram為例 |
以佈署圖(Deployment Diagram)來看的話,就可以更明確地看到整個系統的元件各自是放在哪個機器上
 |
| 常見的Three-tiers架構設計,以佈署圖為例 |
接著如果客戶的線上書店網站系統,希望提供iPhone和Android app的話,系統架構又要怎麼設計才好呢?takeshi的想法是採用Multi-tier架構設計,如下圖所示
 |
| 常見的Multi-tiers架構設計,以佈署圖為例 |
1. On-line Bookstore services
集中統一處理系統的商業邏輯,並且對外提供不同的存取介面(EJB, Webservice等)供不同使用者介面呼叫
2. On-line Bookstore web
供瀏覽器存取的使用者介面(UI, User Interface)
3. iPhone On-line Bookstore app
供iPhone存取的UI
4. Android On-line Bookstore app
供Android Phone存取的UI
5. mySQL-5.5.x
統一資料庫
takeshi認為Multi-tier架構設計的顯而易見的好處在於...
1. 集中商業邏輯統一處理
使用者使用不同的UI (Web、iPhone、Android等),但背後系統的商業邏輯都是一致的;例如使用者選購書籍並下訂單,並不會因為使用UI的不同而有所不同(你並不會因為使用iPhone就可以不用挑選書籍,它不會聰明到幫你挑吧 XD);所以集中商業邏輯統一處理可以讓商業邏輯不會到處發散,也不會到處重複;當然這跟系統設計師(SD, System Designer)的設計能力也有關係啦...
然而UI的頁面和流程會有所不同,這就是每個UI的系統元件要去處理的事囉!
2. 不同角色的系統元件關係在實體邏輯上切分清楚
如果套入tiers的觀念來看待On-line Bookstore web、iPhone On-line Bookstore app和Android On-line Bookstore app系統元件的話,不難發現它們都屬於presentation tier,而On-line Bookstore services則屬於Biz Logic tier和Data Integration tier;所以Multi-tier的架構設計,能夠在系統實體配置上突顯出系統中不同元件所扮演的不同角色;且在溝通介面設計良好的情況下,在更改其中一個系統元件的實作時,不會影響到其它元件;再者,不同的元件被佈署在不同的Server上,可以增加錯誤排除的效率(透過log和Server控管介面等)等
Multi-tier的另外一個更重要的好處,就是 可以透過水平式擴展(Horizontally Scalable,也就是叢集(cluster)啦)的方式,來增加系統的scalability、Availability等;舉以下一些例子
1. 線上書店在上線一陣子之後,發現同時線上使用者人數越來越多而導致系統效率變差,經查詢Web Server的控管介面後發現,Web Server準備的request pool已經被過多的同時上線使用者給占光,導致Web Server必須等待空的request instance來服務使用者的請求,導致整體系統回應時間變長,然而request pool已無法再調大(已達機器上限);此時我們可以選擇新增一個機器來作為Web Server,這樣系統會有兩個Web Server組成的cluster來對外提供服務,這樣一來並能有效處理同時線上使用者人數越來越多的問題。
2. 如上例,線上書店在上線一陣子之後,發現透過Web Server和Smart phone設備的同時線上使用者人數越來越多而導致系統效率變差,經查詢Application Server(AP Server)控管介面後,發現是AP Server運算資源不足,我們同樣地可以考慮再加上一台機器,作為新的AP Server,這樣系統會有兩個AP Server組成的cluster來對外提供服務,這樣一來並能有效處理同時線上使用者人數越來越多的問題。
3.當系統的Web Server或是AP Server突然crash時,cluster中的另一台Server仍可持續運作,雖然系統的效率會降低(直到修復為止),但仍然可以持續提供服務,可以確保系統的availability。
傳統上為了要加強系統的非功能性需求的強度,通常是採取垂直式擴展(Vertical Scalable) ,也就是對一台機器狂加CPU和Memory,亦或是直接換一台更貴的機器來替代;至於要採用哪一種解決方案,需要從成本和技術能力上來作思考,水平式擴展方案的好處是可以使用相當便宜的機器,來組成一個cluster來提供服務;然而要達到前者所提供的運算能力,在垂直式擴展的方案來說,可能需要上百萬元等級的伺服器,才能達到同等級的運算能力。以技術能力來說,以Java平台來說,AP Server要組成cluster其實已經比以前要簡單很多,通常要注意的是AP Server的cluster設定、網路卡等級和路由器等級等;像上圖的AP Server是glassfish,是takeshi相當喜愛的AP Server,它是Oracle的opensource AP server,既免錢能力又強ㄛ(要作cluster也沒問題ㄛ),強力推薦!
takeshi認為阻礙系統水平式擴展的最大問題,其實仍然是開發團隊對系統的設計和實作方式啦...
就以上takeshi的描述提出下圖
 |
| 常見的Multi-tiers + clusters架構設計,以佈署圖為例 |
雖然takeshi不是資料庫管理的專家 ,但仍然可以藉助google大神的力量跟大家作一些分享啦...以下簡述一般關聯式資料庫(RDB, Relational Database)如何採取水平式擴展的方法 (當然朋友們也可以直接採取垂直式擴展的方式啦)
1. 讀寫分離 (主從複製,Master/Slave)
使用多台RDB組成一cluster,一台為Master,其它台為Slave,Master Server負責寫入(write)操作,其它Slave Server負責讀取(read)操作;此概念是基於資料庫的使用,通常是讀取操作的比率比寫入操作要來得高 (例如,讀取線上書店產品的機率,比使用者下訂單要來的高;假如一樣高的話,書店老闆就賺到合不嚨嘴啦 XD);概觀如下圖所示
 |
| RDB的水平式擴展方案,讀寫分離 |
通常在讀寫分離也不符合需求的情況下,就要考慮分庫的作法了 (也就是被逼的啦...);同樣也是舉線上書店的案例,通常線上書店在關聯式模型(Relational Model)的設計下,可能會有客戶資訊、交易資訊和產品類別與庫存等表格,假設今天線上書店的生意超級興隆,導致以上表格的資料量大到已經塞不下在一台Master Server裡了!所以系統維運團隊就不得不採取分庫的方法,來維持線上書店系統的正常運作了。
分庫的概念很簡單,其實就是把資料量大的表格分別拆到不同的DB Server中,以上述案例來說,就是把客戶資訊、交易資訊和產品分類與庫存資訊的表格,分別放置在不同的DB Server中;概觀如下圖所示
 |
| RDB的水平式擴展方案,分庫 |
 |
| RDB的水平式擴展方案,分庫 + 讀寫分離 |
通常在使用了分庫作法也還是不符合需求的情況下,就要考慮分庫分表的作法了 (走到這個地步的話,takeshi真的要恭喜,表示這間公司真的賺很大ㄚ...Orz);同樣如上案例,假使作了分庫之後,產品分類與庫存表格的資料量仍然大到一台DB Server無法承受,此時就需要作分表了。
概念上同樣也很簡單,就是把原來的一張表格,拆分成多張表格啦;概觀如下圖所示,重點是在DB Server4中的表格,是從DB Server3的表格中拆分出來的
 |
| RDB的水平式擴展方案,分庫+分表 |
近年來相當火紅的noSQL DB,也是為了要解決上述等等問題而產生的;據takeshi的了解,hadoop的目的是在提供資訊系統一個可以無限水平擴展分散式檔案系統;HBase則是基於Hadoop,可以無限水平擴展分散式資料庫;另外還有Memcached這類的分散式memory database,用來緩存系統常用的資訊,以進而增加系統的反應時間;總而言之,noSQL DB的產品可是不勝枚舉ㄚ...對超大規模資訊系統架構設計有興趣的朋友,也可以參考High Scalability這個網站,takeshi有時候也會上去晃晃說
這篇文章到這裡也夠長了,takeshi之後有機會再說說noSQL的感想唄~
2012年3月11日 星期日
軟體專案的素質之三 ─ 整體設計之 架構設計篇
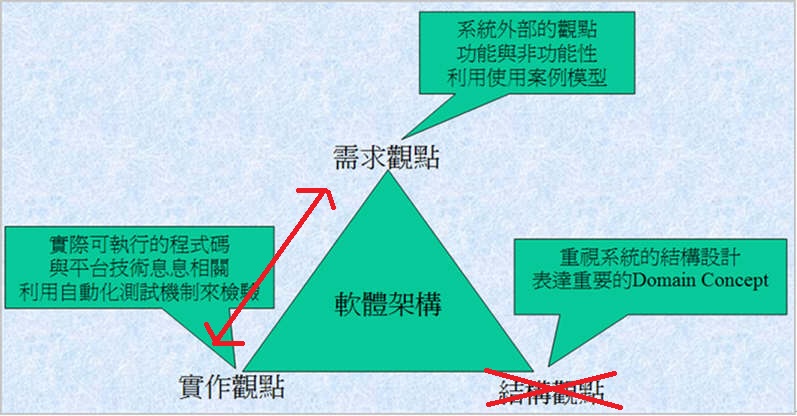
這次takeshi要談的是架構設計,在正式開始討論之前,takeshi要先幫大家refresh一下記憶,之前takeshi討論系統設計的文章,引用了kenming的文章,如下圖...
takeshi也講解過對於 需求、結構和實作觀點的看法,takeshi再舉一個關於"舞台劇"的例子:需求觀點就好比是一齣劇的劇本,而結構觀點就好比是這齣劇的演員,實作觀點就好比是舞台的選擇;我們從導演或編劇(客戶窗口或領域專家)手上拿到劇本(需求收集),然後挑選適合的演員(系統分析),請演員依據劇本作排練(系統設計,takeshi是使用Domain-Driven Design),然後就預期觀眾人數(系統正式上線人數)來決定正式演出的舞台(架構設計);也就是說,舞台劇的預期觀眾人數較少,就使用較簡單的舞台,而預期觀眾人數較多,就使用較大較豪華的舞台
關於劇本的內容和演員的演技,就是藉由不斷的排演(Iteration)來跟導演或編劇作確認與調整;而平常大家都是在排練室作排練來磨練演技(Unit Test, Integrated Test),偶而在正式舞台上作排練來確認最終表演的成果(System Test),必要時也請一些觀眾來參與排練演出(User Acceptance Test);經由不斷的排練,最終是一個博得滿堂彩的演出(成功的專案,客戶滿意、高品質的系統)!
所以說系統的架構設計就是在探討該如何挑選適合的舞台!
那該如何挑選呢? takeshi在這裡分享自己在作系統架構設計時的思考框架
Tiers (欲開發之應用系統的概念分層)
首先,先從欲開發之應用系統(SuD,System under Development)之概念上的分層架構著手,以下這張圖對於JavaEE的developer來說,應該不陌生
以下簡單介紹每個Tiers所負責的工作
Client Tier
指SuD使用者的環境,可能是PC、Browser、Smart Phone等...
Presentation Tier
指SuD的使用者介面,現行應用系統大多是圖形化使用者介面(Graphical User Interface)
Business Tier
指SuD商業邏輯運行的地方,Domain Model也是在這裡運行
Integration Tier
指SuD對其他外部系統互動之邏輯所運行的地方
Resource Tier
指外部系統,可能是其他上下游系統,亦或是資料儲存媒體(資料庫、檔案)等
最左邊的Client Tier是對SuD使用者提供服務,使用者觸發某個事件(例如click button),此事件會產生請求,往右邊 Tier傳送,一層接著一層,直到SuD把請求處理完;接著再往左邊 Tier回傳,又一層接著一層,傳回到SuD使用者看到回應,接著使用者再對SuD繼續執行下一個步驟,因此又觸發新的事件,SuD再接著處理;此一連串步驟不斷執行,直到使用者把他/她的目的達到為止
舉個例子,使用者使用瀏覽器(Client Tier)在線上書店網站(Presentation Tier)購物,已在購物車中挑選好想要購買的書籍, 接著點選「結帳」連結,觸發使用者介面事件,事件產生請求(request),並傳送到SuD的Business Tier;SuD商業邏輯要幫使用者產生訂單,會跟Integration Tier請求使用者資訊(地址、電話等)、書籍價格、運費資訊等,接著Integration Tier會跟資料庫(Resource Tier)請求相關資料,再回傳給Business Tier;Business Tier把這些相關資料包裝起來,再一起送到Presentation Tier,在線上書店網站呈現出填寫訂單頁面;等待著使用者填寫訂單,並觸發下一個事件;上述類似流程會不斷執行,一直到使用者把他/她的訂單完成(達到目的)為止
如上所述,把一個SuD拆解成多個Tier,其主要原因如下
降低複雜度
這是人類處理複雜問題的一般處理手法;把一個龐大的複雜問題,照一定的邏輯和相關性作分解和歸類,拆成一個個小型問題,再來針對這些小型問題來想解決方案,問題複雜度會因此降低很多,也就是要分而治之 (divide and conquer)
鬆散耦合和提高內聚力(Loosely-coupled & Highly-cohesive)
這是物件導向設計原則都會提醒的概念,我們在作系統設計時,類別之間要相依於介面而不是實作,和每個類別所負責的操作是否適當,如此才能提高類別之間的彈性和盡量縮小因需求變動而產生的設計變動範圍;然而在設計SuD之間的Tier的相依性時,也是同樣的道理;每一 Tier都會提供介面來對下一個 Tier提供服務;例如當SuD的Resource Tier對外部系統的呼叫,其外部系統的介面從原本的JDBC呼叫,換成了Web Service技術,我們只要抽換此Resource Tier的相關實作即可,SuD的其他Tier皆不會受影響
實務經驗分享
就takeshi在實務上的經驗,其實在業界待過一陣子的developer,大多都知道這個東東,但對為啥要這麼作卻不甚了解,所以到後來的概念分層,變成了單純地只是在命名空間(在Java是指package)上的區別,然而實作之間的相依性卻藕斷絲連,舉一些例子如下...
1. Data Integration Tier使用了DAO pattern(Data Access Object),但卻在Business Tier組裝SQL語法,當作DAO物件方法的參數;試問假如遇到了takeshi剛舉出的例子(從JDBC換成Web Service)時,那是不是連同Business Tier也受到影響了呢?
2. 同樣也是DAO的例子,takeshi也看過直接從DAO方法回傳ResultSet物件出來的...
3. 還有一種是比較不明顯的例子,就是在DAO中直接用SQL組成SuD UI的資料需求,然後直接往前端Tier回傳,而Business Tier單純只是為了要接收request、呼叫DAO,接著把資料往前回傳;就takeshi的觀察,主要會有以下問題衍生...
3.1 SQL語法會異常複雜,並且類似語法會散佈在整個DAO都是(或是散佈在資料庫端),一旦使用者介面有修改需求,必須要搜尋整個DAO tier,確保相關修改資料的SQL語法都有調整到
3.2 一旦SQL語法查詢無法滿足UI需求時,就會在Business Tier作資料組裝的工作,通常此類型的資料組裝邏輯,可讀性相當低;原本複雜的SQL + 到處散佈在DAO Tier + Business Tier的資料組裝的可讀性低,大大地增加系統維護的複雜度!
Layers (平台服務的分層)
接下來takeshi要分享的是各階層平台要提供哪些服務來支持SuD的需求;要聚焦的是SuD的每個Tier,在每一個Layer需要哪些服務,是一種二維的概念,如下圖所示
有在追蹤takeshi部落格的朋友,相信對這張圖有點眼熟,這是Java MVC sample#2的Tiers & Layers Diagram,takeshi借用這張圖來對每個Layer所代表的意義作個簡單介紹
Application Layer
描述SuD的軟體元件;參考上圖,從Client tier到Data Integration tier就是Sample Project #2和Resource tier的DB Schema
Virtual Platform
描述SuD所相依之平台所提供的介面 ;參考上圖,在Client tier是基於html v4.0,而在Presentation tier則是AS v3、MXML和PureMVC-AS3-2.0.4,之後以此類推...
Upper Platform
描述SuD所相依之平台本身;參考上圖,在Client tier是基於任何廠牌的瀏覽器(Any browser)和Adobe Flash Player v10的版本
Lower Platform
描述SuD所相依的作業系統(OS,Operating System);參考上圖,Client tier是可以是任何OS,而SuD也是任何OS;另外要注意的是,Client tier和Presentation ~ Resources tier是拆分為兩個儲存格,其實是代表在不同的電腦上運作的意思
Hardware Platform
描述SuD所相依的電腦規格;參考上圖,不論是Client tier或是Presentation ~ Resources tier都可以是任何電腦
takeshi在實務上會使用tiers & layers diagram或是UML的佈署圖來記錄以上資訊
Service-Level Requirements/Quality Of Service (QoS)
在這一節,takeshi要分享的系統架構設計最大的主角,也就是系統的非功能性需求,簡單介紹如下...
Performance
描述客戶期望SuD對於需求的反應時間;例如,當使用者在線上書店下訂單時,對訂單的處理必須要在三秒內完成,並把結果呈現給使用者知道!
Scalability
描述SuD對於需求的吞吐量,也就是在同一時間單位可同時處理多少需求,同時又能滿足Performance需求;例如,客戶希望SuD有每秒鐘可以同時處理一千位使用者的需求,又能滿足三秒鐘內回覆給使用者知道的能力!
Reliability
描述SuD對於交易處理的完整性與一致性;例如,客戶當然對於SuD保存客戶資料和交易資料相當重視;另外一方面,對於SuD所產生出來的log檔案,其數量可能是最多的,但客戶可能對其儲存的完整性與一致性的要求,相對就沒這麼高;所以對於兩者資料的儲存方式有機會可以採取不同的作法
Availability
描述SuD可以一直提供服務的程度;像是Amozon的EC2服務,保證可以在訂閱之後的365天內,提供99.95%的Availability,換句話說,每年大概約有四個小時,服務會有無法提供的可能性
Security
描述SuD提供的安全性機制;通常客戶會要求SuD,對於使用者敏感資料操作必須要提供SSL連線方式;另外也可能會要求儲存在資料庫的使用者密碼,應該要使用演算法加密,防止可以存取資料庫的相關人員盜竊
實務經驗分享
takeshi在實務上的經驗是,通常系統分析師(System Analyst,SA)在跟客戶窗口搜集需求時,往往都聚焦在功能性需求,而對非功能性需求都比較少關注;當系統進入使用者接受度測試(User Acceptance Test)時,非功能性需求的瓶頸才被關注,然而在此階段才去解決此問題,時間往往都已經不夠用;並且改善非功能性需求的問題,動到系統設計的可能性是高的;通常會演變成開發團隊要卯起來加班,最後就算SuD如期上線,但背後的系統設計可能已經受到影響,對往後的維護工作造成影響
所以對於非功能性需求的部分,應當及早釐清,並在系統開發的過程中,就要盡量做到非功能性的系統測試(System Test);以Java平台而言,takeshi建議可考慮使用類似像Apache JMeter等軟體,來作非功能性測試
SunTone Methodology
以上takeshi介紹的從三個思考框架來看待系統架構,其實可以使用三維的方塊(cube)來表達,如下圖所示
上圖的x軸就是指Tiers,y軸就是Layers,而z軸就是QoS;其實這是昇陽提出來的系統架構設計方法,叫做「SunTone Methodology」,有興趣的朋友可以參考這裡,或者是可以去上OO-226的課程,takeshi在這門課程學到不少東東說~
takeshi在選擇和設計系統架構時,就是依據此cube來作思考的,對takeshi相當有幫助,希望也對看到此篇文章的朋友們也有幫助囉 ^^
 |
| {程序員邀稿} 以架構為中心的主要設計產出(1),Kenming's鮮思維 |
關於劇本的內容和演員的演技,就是藉由不斷的排演(Iteration)來跟導演或編劇作確認與調整;而平常大家都是在排練室作排練來磨練演技(Unit Test, Integrated Test),偶而在正式舞台上作排練來確認最終表演的成果(System Test),必要時也請一些觀眾來參與排練演出(User Acceptance Test);經由不斷的排練,最終是一個博得滿堂彩的演出(成功的專案,客戶滿意、高品質的系統)!
所以說系統的架構設計就是在探討該如何挑選適合的舞台!
那該如何挑選呢? takeshi在這裡分享自己在作系統架構設計時的思考框架
Tiers (欲開發之應用系統的概念分層)
首先,先從欲開發之應用系統(SuD,System under Development)之概念上的分層架構著手,以下這張圖對於JavaEE的developer來說,應該不陌生
 |
| SuD的tiers,本blog整理 |
Client Tier
指SuD使用者的環境,可能是PC、Browser、Smart Phone等...
Presentation Tier
指SuD的使用者介面,現行應用系統大多是圖形化使用者介面(Graphical User Interface)
Business Tier
指SuD商業邏輯運行的地方,Domain Model也是在這裡運行
Integration Tier
指SuD對其他外部系統互動之邏輯所運行的地方
Resource Tier
指外部系統,可能是其他上下游系統,亦或是資料儲存媒體(資料庫、檔案)等
最左邊的Client Tier是對SuD使用者提供服務,使用者觸發某個事件(例如click button),此事件會產生請求,往右邊 Tier傳送,一層接著一層,直到SuD把請求處理完;接著再往左邊 Tier回傳,又一層接著一層,傳回到SuD使用者看到回應,接著使用者再對SuD繼續執行下一個步驟,因此又觸發新的事件,SuD再接著處理;此一連串步驟不斷執行,直到使用者把他/她的目的達到為止
舉個例子,使用者使用瀏覽器(Client Tier)在線上書店網站(Presentation Tier)購物,已在購物車中挑選好想要購買的書籍, 接著點選「結帳」連結,觸發使用者介面事件,事件產生請求(request),並傳送到SuD的Business Tier;SuD商業邏輯要幫使用者產生訂單,會跟Integration Tier請求使用者資訊(地址、電話等)、書籍價格、運費資訊等,接著Integration Tier會跟資料庫(Resource Tier)請求相關資料,再回傳給Business Tier;Business Tier把這些相關資料包裝起來,再一起送到Presentation Tier,在線上書店網站呈現出填寫訂單頁面;等待著使用者填寫訂單,並觸發下一個事件;上述類似流程會不斷執行,一直到使用者把他/她的訂單完成(達到目的)為止
如上所述,把一個SuD拆解成多個Tier,其主要原因如下
降低複雜度
這是人類處理複雜問題的一般處理手法;把一個龐大的複雜問題,照一定的邏輯和相關性作分解和歸類,拆成一個個小型問題,再來針對這些小型問題來想解決方案,問題複雜度會因此降低很多,也就是要分而治之 (divide and conquer)
鬆散耦合和提高內聚力(Loosely-coupled & Highly-cohesive)
這是物件導向設計原則都會提醒的概念,我們在作系統設計時,類別之間要相依於介面而不是實作,和每個類別所負責的操作是否適當,如此才能提高類別之間的彈性和盡量縮小因需求變動而產生的設計變動範圍;然而在設計SuD之間的Tier的相依性時,也是同樣的道理;每一 Tier都會提供介面來對下一個 Tier提供服務;例如當SuD的Resource Tier對外部系統的呼叫,其外部系統的介面從原本的JDBC呼叫,換成了Web Service技術,我們只要抽換此Resource Tier的相關實作即可,SuD的其他Tier皆不會受影響
實務經驗分享
就takeshi在實務上的經驗,其實在業界待過一陣子的developer,大多都知道這個東東,但對為啥要這麼作卻不甚了解,所以到後來的概念分層,變成了單純地只是在命名空間(在Java是指package)上的區別,然而實作之間的相依性卻藕斷絲連,舉一些例子如下...
1. Data Integration Tier使用了DAO pattern(Data Access Object),但卻在Business Tier組裝SQL語法,當作DAO物件方法的參數;試問假如遇到了takeshi剛舉出的例子(從JDBC換成Web Service)時,那是不是連同Business Tier也受到影響了呢?
2. 同樣也是DAO的例子,takeshi也看過直接從DAO方法回傳ResultSet物件出來的...
3. 還有一種是比較不明顯的例子,就是在DAO中直接用SQL組成SuD UI的資料需求,然後直接往前端Tier回傳,而Business Tier單純只是為了要接收request、呼叫DAO,接著把資料往前回傳;就takeshi的觀察,主要會有以下問題衍生...
3.1 SQL語法會異常複雜,並且類似語法會散佈在整個DAO都是(或是散佈在資料庫端),一旦使用者介面有修改需求,必須要搜尋整個DAO tier,確保相關修改資料的SQL語法都有調整到
3.2 一旦SQL語法查詢無法滿足UI需求時,就會在Business Tier作資料組裝的工作,通常此類型的資料組裝邏輯,可讀性相當低;原本複雜的SQL + 到處散佈在DAO Tier + Business Tier的資料組裝的可讀性低,大大地增加系統維護的複雜度!
Layers (平台服務的分層)
接下來takeshi要分享的是各階層平台要提供哪些服務來支持SuD的需求;要聚焦的是SuD的每個Tier,在每一個Layer需要哪些服務,是一種二維的概念,如下圖所示
 |
| Tiers & Layers Diagram,本blog整裡 |
有在追蹤takeshi部落格的朋友,相信對這張圖有點眼熟,這是Java MVC sample#2的Tiers & Layers Diagram,takeshi借用這張圖來對每個Layer所代表的意義作個簡單介紹
Application Layer
描述SuD的軟體元件;參考上圖,從Client tier到Data Integration tier就是Sample Project #2和Resource tier的DB Schema
Virtual Platform
描述SuD所相依之平台所提供的介面 ;參考上圖,在Client tier是基於html v4.0,而在Presentation tier則是AS v3、MXML和PureMVC-AS3-2.0.4,之後以此類推...
Upper Platform
描述SuD所相依之平台本身;參考上圖,在Client tier是基於任何廠牌的瀏覽器(Any browser)和Adobe Flash Player v10的版本
Lower Platform
描述SuD所相依的作業系統(OS,Operating System);參考上圖,Client tier是可以是任何OS,而SuD也是任何OS;另外要注意的是,Client tier和Presentation ~ Resources tier是拆分為兩個儲存格,其實是代表在不同的電腦上運作的意思
Hardware Platform
描述SuD所相依的電腦規格;參考上圖,不論是Client tier或是Presentation ~ Resources tier都可以是任何電腦
takeshi在實務上會使用tiers & layers diagram或是UML的佈署圖來記錄以上資訊
Service-Level Requirements/Quality Of Service (QoS)
在這一節,takeshi要分享的系統架構設計最大的主角,也就是系統的非功能性需求,簡單介紹如下...
Performance
描述客戶期望SuD對於需求的反應時間;例如,當使用者在線上書店下訂單時,對訂單的處理必須要在三秒內完成,並把結果呈現給使用者知道!
Scalability
描述SuD對於需求的吞吐量,也就是在同一時間單位可同時處理多少需求,同時又能滿足Performance需求;例如,客戶希望SuD有每秒鐘可以同時處理一千位使用者的需求,又能滿足三秒鐘內回覆給使用者知道的能力!
Reliability
描述SuD對於交易處理的完整性與一致性;例如,客戶當然對於SuD保存客戶資料和交易資料相當重視;另外一方面,對於SuD所產生出來的log檔案,其數量可能是最多的,但客戶可能對其儲存的完整性與一致性的要求,相對就沒這麼高;所以對於兩者資料的儲存方式有機會可以採取不同的作法
Availability
描述SuD可以一直提供服務的程度;像是Amozon的EC2服務,保證可以在訂閱之後的365天內,提供99.95%的Availability,換句話說,每年大概約有四個小時,服務會有無法提供的可能性
Security
描述SuD提供的安全性機制;通常客戶會要求SuD,對於使用者敏感資料操作必須要提供SSL連線方式;另外也可能會要求儲存在資料庫的使用者密碼,應該要使用演算法加密,防止可以存取資料庫的相關人員盜竊
實務經驗分享
takeshi在實務上的經驗是,通常系統分析師(System Analyst,SA)在跟客戶窗口搜集需求時,往往都聚焦在功能性需求,而對非功能性需求都比較少關注;當系統進入使用者接受度測試(User Acceptance Test)時,非功能性需求的瓶頸才被關注,然而在此階段才去解決此問題,時間往往都已經不夠用;並且改善非功能性需求的問題,動到系統設計的可能性是高的;通常會演變成開發團隊要卯起來加班,最後就算SuD如期上線,但背後的系統設計可能已經受到影響,對往後的維護工作造成影響
所以對於非功能性需求的部分,應當及早釐清,並在系統開發的過程中,就要盡量做到非功能性的系統測試(System Test);以Java平台而言,takeshi建議可考慮使用類似像Apache JMeter等軟體,來作非功能性測試
SunTone Methodology
以上takeshi介紹的從三個思考框架來看待系統架構,其實可以使用三維的方塊(cube)來表達,如下圖所示
 |
| SunTone Cube |
takeshi在選擇和設計系統架構時,就是依據此cube來作思考的,對takeshi相當有幫助,希望也對看到此篇文章的朋友們也有幫助囉 ^^
2012年2月21日 星期二
HBase-0.90.4 本機測試
上一篇takeshi談到如何在Hadoop上作本機測試,這次takeshi要談的是如何在HBase作本機測試,這也是takeshi目前專案正在使用的解決方案
此解決方案的採用,幫助團隊在複雜的mapReduce演算法研究和開發上,帶來相當大的效益;接下來,takeshi打算把原本相依於外部HBase環境和相關測試資料的功能性測試程式,重構成此解決方案的版本
廢話不多說,接下來就介紹HBase本機測試的作法吧!
前提
1. 環境是HBase-0.90.4
2. 本解法參考的資料來源在這裡,此篇blog介紹了如何使用HBaseTestingUtility類別來初始local mini-cluster instance和使用ImportTsv類別來建構測試資料的方法;另外也參考了HBase的source code
準備工作
1. 誠如上一篇所講,如果是Windows環境的朋友,請先安裝cygwin
2. takeshi已把sample code整理成maven專案,檔案在這裡
2.1 要運行此專案需要使用maven, 請參考maven官網,或者也可以參考takeshi的文章ㄛ(打一下廣告^^)
2.2 假如朋友們要把maven專案 import到eclispe的話,要先在eclispe裝上m2eclispe plug-in
執行測試程式
把zip檔載下來後,解壓縮到你想放置的路徑(假設是$PROJECT_HOME),接著進入命令列模式(Command Line Interface, CLI),進入$PROJECT_HOME路徑,執行mvn clean test,接著maven便會開始啟動HBase本機測試程式囉!
測試程式簡介
專案裡有三支測試程式,分別簡介如下...
AbstractHBaseMiniClusterTest
從名稱也看得出來,是一支抽象類別(Abstract Class),它把啟動和關閉HBaseTestingUtility類別的工作封裝在裡面,並另外提供一些工具方法(utility methods),另外兩支測試程式的super-class,程式碼如下...
FromClientSideTest
從HBase專案的測試程式借過來的,可以確認mini-cluster的可用性,這支測試程式提供了相當多的方法,如果在developer的本機環境都測過的話,表示mini-cluster是沒有問題的囉~
HBaseMiniClusterTest
這支測試程式是為了驗證ImportTsv類別的正確性所寫的,朋友們可以借由此測試程式來了解如何把測試資料倒入本機的mini-cluster,程式碼如下...
心得分享
這次takeshi為了要找到本機測試解決方案,花了不少時間在trace HBase的source code,takeshi要跟大家分享的是,現在的opensource專案都遵守測試先行開發(Test Driven Development,TDD),除了對於開發團隊來說是程式品質的保證之外,對於takeshi這種「體制外的路人甲 XD」來說,這些測試程式也是「重要的文件ㄛ」!
例如,takeshi在研究HBaseTestingUtility和ImportTsv類別時,就是藉由它們的單元測試程式中的輸出入值和斷言(Assertion) ,來推導出它們的使用方法的,這也是takeshi提倡TDD的主要因素之一啦~
希望這些東東能幫助到正在看這篇文章的你/妳囉 ^^
此解決方案的採用,幫助團隊在複雜的mapReduce演算法研究和開發上,帶來相當大的效益;接下來,takeshi打算把原本相依於外部HBase環境和相關測試資料的功能性測試程式,重構成此解決方案的版本
廢話不多說,接下來就介紹HBase本機測試的作法吧!
前提
1. 環境是HBase-0.90.4
2. 本解法參考的資料來源在這裡,此篇blog介紹了如何使用HBaseTestingUtility類別來初始local mini-cluster instance和使用ImportTsv類別來建構測試資料的方法;另外也參考了HBase的source code
準備工作
1. 誠如上一篇所講,如果是Windows環境的朋友,請先安裝cygwin
2. takeshi已把sample code整理成maven專案,檔案在這裡
2.1 要運行此專案需要使用maven, 請參考maven官網,或者也可以參考takeshi的文章ㄛ(打一下廣告^^)
2.2 假如朋友們要把maven專案 import到eclispe的話,要先在eclispe裝上m2eclispe plug-in
執行測試程式
把zip檔載下來後,解壓縮到你想放置的路徑(假設是$PROJECT_HOME),接著進入命令列模式(Command Line Interface, CLI),進入$PROJECT_HOME路徑,執行mvn clean test,接著maven便會開始啟動HBase本機測試程式囉!
測試程式簡介
專案裡有三支測試程式,分別簡介如下...
AbstractHBaseMiniClusterTest
從名稱也看得出來,是一支抽象類別(Abstract Class),它把啟動和關閉HBaseTestingUtility類別的工作封裝在裡面,並另外提供一些工具方法(utility methods),另外兩支測試程式的super-class,程式碼如下...
public abstract class AbstractHBaseMiniClusterTest {
//a static constant property for HBaseTestingUtility instance
protected final static HBaseTestingUtility TEST_UTIL = new HBaseTestingUtility();
@BeforeClass
public static void setUpBeforeClass() throws Exception {
//start mini-cluster instance for 3 datanodes
TEST_UTIL.startMiniCluster(3);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
//shutdown mini-cluster instance
TEST_UTIL.shutdownMiniCluster();
}
//following are utility methods...
FromClientSideTest
從HBase專案的測試程式借過來的,可以確認mini-cluster的可用性,這支測試程式提供了相當多的方法,如果在developer的本機環境都測過的話,表示mini-cluster是沒有問題的囉~
HBaseMiniClusterTest
這支測試程式是為了驗證ImportTsv類別的正確性所寫的,朋友們可以借由此測試程式來了解如何把測試資料倒入本機的mini-cluster,程式碼如下...
public class HBaseMiniClusterTest extends AbstractHBaseMiniClusterTest {
@BeforeClass
public static void setUpBeforeClass() throws Exception {
//start mini-cluster
AbstractHBaseMiniClusterTest.setUpBeforeClass();
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
//shutdown mini-cluster
AbstractHBaseMiniClusterTest.tearDownAfterClass();
}
@Test //a test method for test data dumping
public void testImportCompanyInfo() throws Exception {
//prepare parameters
//...
//dump test data into mini-cluster
importLocalFile2Table(conf, args, INPUT_FILE, INPUT_FILE_PATH);
//...
//validate the test data
//...
}
心得分享
這次takeshi為了要找到本機測試解決方案,花了不少時間在trace HBase的source code,takeshi要跟大家分享的是,現在的opensource專案都遵守測試先行開發(Test Driven Development,TDD),除了對於開發團隊來說是程式品質的保證之外,對於takeshi這種「體制外的路人甲 XD」來說,這些測試程式也是「重要的文件ㄛ」!
例如,takeshi在研究HBaseTestingUtility和ImportTsv類別時,就是藉由它們的單元測試程式中的輸出入值和斷言(Assertion) ,來推導出它們的使用方法的,這也是takeshi提倡TDD的主要因素之一啦~
希望這些東東能幫助到正在看這篇文章的你/妳囉 ^^
2012年2月20日 星期一
Hadoop-0.20.x 本機測試
由於最近takeshi的專案主要是基於Hadoop和HBase平台上開發應用,所以不免俗地,我們需要對我們的應用作功能性上的測試;要執行我們的測試程式,必須要有以下步驟...
1. 必須要在環境中架一個Hadoop + HBase的cluster
2. 並且要在此cluster倒入事先定義好的測試資料
3. 接著在我們專案的maven pom檔中,把相關參數(Zookeeper的IP和port)設定好
4. 執行測試(也就是執行mvn clean verify)
5. 之後maven會幫我們執行所有的單元測試和整合測試,可以經過驗證輸出的值(assertion),來確認程式運作是否合乎我們預期
上述流程跑起來還算順暢,但仍有以下幾點會造成我們的困擾
1. 當其他團隊要參與我們的專案時,必須要跟我們索取測試資料(20GB... XD),並倒在HBase裡
2. 測試程式出錯時,很難debug!因為程式會被copy到參與工作的遠端節點再執行(分散式運算);所以developer在IDE中,對於想要debug的程式主要邏輯區塊下中斷點(breakpoint)時,往往都攔截不到執行緒(running thread),因為這些程式主要邏輯區塊都是在遠端節點執行的!
上述的第2點,是我們非常頭痛的issue,因為專案的商業邏輯越來越複雜,假如不能對這些程式主要邏輯區塊作debug的話,之後會嚴重拖慢開發進度>"<
也因此takeshi花了不少時間,看了相關書籍和網站,最後終於找到解法了!原來不論是Hadoop或是HBase,他們自己在開發的時候,也有相關的困擾,所以寫了一些類別,來專門在測試程式中起在本機跑的mini-cluster,因為是在同一個VM的instance,所以developer也有辦法對Hadoop或是HBase的cluster作debug囉!
不過這次takeshi先分享Hadoop的部分,之後再分享HBase的部分囉~
前提
1. 我們專案使用的環境是Hadoop-0.20.203.0
2. 本解法參考自書籍 Hadoop: The Definitive Guide, Second Edition,作者Tom White的sample code在這裡
準備工作
1.如果是windows環境的朋友,要請你們先安裝cygwin,載點在這裡
1.1 安裝完畢後,必須要把%CYGWIN_HOME% \bin路徑,加到PATH環境變數中
1.2 因為hadoop主要還是在unix-like的環境上執行,所以必須要在wnidows上模擬unix-like環境
2. 把作者的sample code import到IDE中(takeshi使用的是eclipse),並且把以下jar檔加入到build path裡
hadoop-0.20.2
hadoop-0.20.2-ant.jar
hadoop-0.20.2-core.jar
hadoop-0.20.2-examples.jar
hadoop-0.20.2-test.jar
hadoop-0.20.2-tools.jar
lib\commons-cli-1.2.jar
lib\commons-codec-1.3.jar
lib\commons-el-1.0.jar
lib\commons-httpclient-3.0.1.jar
lib\commons-logging-1.0.4.jar
lib\commons-logging-api-1.0.4.jar
lib\commons-net-1.4.1.jar
lib\core-3.1.1.jar
lib\hsqldb-1.8.0.10.jar
lib\jasper-compiler-5.5.12.jar
lib\jasper-runtime-5.5.12.jar
lib\jets3t-0.6.1.jar
lib\jetty-6.1.14.jar
lib\jetty-util-6.1.14.jar
lib\junit-3.8.1.jar
lib\kfs-0.2.2.jar
lib\log4j-1.2.15.jar
lib\mockito-all-1.8.0.jar
lib\oro-2.0.8.jar
lib\servlet-api-2.5-6.1.14.jar
lib\slf4j-api-1.4.3.jar
lib\slf4j-log4j12-1.4.3.jar
lib\xmlenc-0.52.jar
apache-tomcat-6.0.32
lib\jsp-api.jar
lib\servlet-api.jar
hamcrest-1.3.0RC2
hamcrest-all-1.3.0RC2.jar
以上的jar檔應該還可以再作刪減,或是應該可以再整理成maven pom檔, 但 takeshi很懶沒有做這個動作啦:p
眼明的朋友應該發現到為啥takeshi include的jar檔是hadoop-0.20.2,而不是hadoop-0.20.203.0,因為203的版本在windows上跑mini-cluster會出錯誤(不過討論網頁的連結在哪takeshi突然找不到了XD),所以takeshi是使用0.20.2來跑mini-cluster的;如果朋友們有其他的解,也請教一下takeshi喔
MiniDFSCluster
可以在本機起HDFS的mini-cluster instance,方便developer作本機debug,API doc在這邊,接著看看剛剛import的sample code專案中的ch03/src/main/java/路徑的CoherencyModelTest.java檔案,使用以下方式來啟動MiniDFSCluster類別
ClusterMapReduceTestCase
它是一個抽象測試類別,使用JUnit3的架構來啟動(當然JUnit4也可以使用囉),它預設會在本機起一個包含兩個節點的mini-cluster instance,方便developer作本機mapReduce 測試和debug,API doc在這邊,接著看看剛剛import的sample code專案中的ch05/src/main/java/v3/路徑的ClusterMapReduceTestCase.java檔案,使用以下方式來啟動此測試類別
細節的部分就請各位朋友去參考程式碼和書籍囉~
以下影片是takeshi在自己本機跑mini-cluster的情形,供大家參考囉~
最後takeshi在專案中採用的是使用HBase的解法(打算下一篇會寫),所以hadoop的source code就沒特別整理了,不過直接使用Tom White的source code,takeshi相信對大家的幫助更大唄~
1. 必須要在環境中架一個Hadoop + HBase的cluster
2. 並且要在此cluster倒入事先定義好的測試資料
3. 接著在我們專案的maven pom檔中,把相關參數(Zookeeper的IP和port)設定好
4. 執行測試(也就是執行mvn clean verify)
5. 之後maven會幫我們執行所有的單元測試和整合測試,可以經過驗證輸出的值(assertion),來確認程式運作是否合乎我們預期
上述流程跑起來還算順暢,但仍有以下幾點會造成我們的困擾
1. 當其他團隊要參與我們的專案時,必須要跟我們索取測試資料(20GB... XD),並倒在HBase裡
2. 測試程式出錯時,很難debug!因為程式會被copy到參與工作的遠端節點再執行(分散式運算);所以developer在IDE中,對於想要debug的程式主要邏輯區塊下中斷點(breakpoint)時,往往都攔截不到執行緒(running thread),因為這些程式主要邏輯區塊都是在遠端節點執行的!
上述的第2點,是我們非常頭痛的issue,因為專案的商業邏輯越來越複雜,假如不能對這些程式主要邏輯區塊作debug的話,之後會嚴重拖慢開發進度>"<
也因此takeshi花了不少時間,看了相關書籍和網站,最後終於找到解法了!原來不論是Hadoop或是HBase,他們自己在開發的時候,也有相關的困擾,所以寫了一些類別,來專門在測試程式中起在本機跑的mini-cluster,因為是在同一個VM的instance,所以developer也有辦法對Hadoop或是HBase的cluster作debug囉!
不過這次takeshi先分享Hadoop的部分,之後再分享HBase的部分囉~
前提
1. 我們專案使用的環境是Hadoop-0.20.203.0
2. 本解法參考自書籍 Hadoop: The Definitive Guide, Second Edition,作者Tom White的sample code在這裡
準備工作
1.如果是windows環境的朋友,要請你們先安裝cygwin,載點在這裡
1.1 安裝完畢後,必須要把%CYGWIN_HOME% \bin路徑,加到PATH環境變數中
1.2 因為hadoop主要還是在unix-like的環境上執行,所以必須要在wnidows上模擬unix-like環境
2. 把作者的sample code import到IDE中(takeshi使用的是eclipse),並且把以下jar檔加入到build path裡
hadoop-0.20.2
hadoop-0.20.2-ant.jar
hadoop-0.20.2-core.jar
hadoop-0.20.2-examples.jar
hadoop-0.20.2-test.jar
hadoop-0.20.2-tools.jar
lib\commons-cli-1.2.jar
lib\commons-codec-1.3.jar
lib\commons-el-1.0.jar
lib\commons-httpclient-3.0.1.jar
lib\commons-logging-1.0.4.jar
lib\commons-logging-api-1.0.4.jar
lib\commons-net-1.4.1.jar
lib\core-3.1.1.jar
lib\hsqldb-1.8.0.10.jar
lib\jasper-compiler-5.5.12.jar
lib\jasper-runtime-5.5.12.jar
lib\jets3t-0.6.1.jar
lib\jetty-6.1.14.jar
lib\jetty-util-6.1.14.jar
lib\junit-3.8.1.jar
lib\kfs-0.2.2.jar
lib\log4j-1.2.15.jar
lib\mockito-all-1.8.0.jar
lib\oro-2.0.8.jar
lib\servlet-api-2.5-6.1.14.jar
lib\slf4j-api-1.4.3.jar
lib\slf4j-log4j12-1.4.3.jar
lib\xmlenc-0.52.jar
apache-tomcat-6.0.32
lib\jsp-api.jar
lib\servlet-api.jar
hamcrest-1.3.0RC2
hamcrest-all-1.3.0RC2.jar
以上的jar檔應該還可以再作刪減,或是應該可以再整理成maven pom檔, 但 takeshi很懶沒有做這個動作啦:p
眼明的朋友應該發現到為啥takeshi include的jar檔是hadoop-0.20.2,而不是hadoop-0.20.203.0,因為203的版本在windows上跑mini-cluster會出錯誤(不過討論網頁的連結在哪takeshi突然找不到了XD),所以takeshi是使用0.20.2來跑mini-cluster的;如果朋友們有其他的解,也請教一下takeshi喔
MiniDFSCluster
可以在本機起HDFS的mini-cluster instance,方便developer作本機debug,API doc在這邊,接著看看剛剛import的sample code專案中的ch03/src/main/java/路徑的CoherencyModelTest.java檔案,使用以下方式來啟動MiniDFSCluster類別
public class CoherencyModelTest {
// use an in-process HDFS cluster for testing
private MiniDFSCluster cluster;
private FileSystem fs;
@Before
public void setUp() throws IOException {
Configuration conf = new Configuration();
//config parameters setting for test
if (System.getProperty("test.build.data") == null) {
System.setProperty("test.build.data", "/tmp");
}
cluster = new MiniDFSCluster(conf, 1, true, null);
fs = cluster.getFileSystem();
}
@After
public void tearDown() throws IOException {
fs.close();
//shutdown HDFS cluster
cluster.shutdown();
}
//put your test codes below...
}
ClusterMapReduceTestCase
它是一個抽象測試類別,使用JUnit3的架構來啟動(當然JUnit4也可以使用囉),它預設會在本機起一個包含兩個節點的mini-cluster instance,方便developer作本機mapReduce 測試和debug,API doc在這邊,接著看看剛剛import的sample code專案中的ch05/src/main/java/v3/路徑的ClusterMapReduceTestCase.java檔案,使用以下方式來啟動此測試類別
// A test for MaxTemperatureDriver that runs in a "mini" HDFS and MapReduce cluster
public class MaxTemperatureDriverMiniTest extends ClusterMapReduceTestCase {
@Override
protected void setUp() throws Exception {
//config setting for testcase
if (System.getProperty("test.build.data") == null) {
System.setProperty("test.build.data", "/tmp");
}
if (System.getProperty("hadoop.log.dir") == null) {
System.setProperty("hadoop.log.dir", "/build/test/logs");
}
super.setUp();
}
//no need to extends the tearDown method due to the super-class handles it for you
//protected void tearDown() throws Exception
// Not marked with @Test since ClusterMapReduceTestCase is a JUnit 3 test case
public void test() throws Exception {
//...put your test code here
}
}
細節的部分就請各位朋友去參考程式碼和書籍囉~
以下影片是takeshi在自己本機跑mini-cluster的情形,供大家參考囉~
最後takeshi在專案中採用的是使用HBase的解法(打算下一篇會寫),所以hadoop的source code就沒特別整理了,不過直接使用Tom White的source code,takeshi相信對大家的幫助更大唄~
2012年2月19日 星期日
實體關係圖與關聯式資料庫設計
本週takeshi跟公司同事分享了在專案經常用到的基本觀念,也就是我們要如何基於問題領域來設計資料庫模型,presentation如下...
3~5頁講解何謂抽象化,例子是takeshi跟李老師借來的,他是takeshi資料庫的啟蒙導師,takeshi在李老師身上學到很多,非常感謝Orz
12~24頁,是一個給大家熱身的案例,此案例是從資料庫的聖經「資料庫系統原理」借來的,takeshi嘗試一步一步地來引導大家,如何從ER-Model轉換成Relational Model
25~28頁,是一個貼近實務的案例,此案例是一個線上書店系統的類別圖(Class Diagram)(也是takeshi論文的一部分啦:p),其中有複雜的繼承和樹狀遞迴的概念,takeshi使用JPA(Java Persistence API),來把它們轉換成Relational Model
希望對有興趣的朋友有點幫助囉 ^^
3~5頁講解何謂抽象化,例子是takeshi跟李老師借來的,他是takeshi資料庫的啟蒙導師,takeshi在李老師身上學到很多,非常感謝Orz
12~24頁,是一個給大家熱身的案例,此案例是從資料庫的聖經「資料庫系統原理」借來的,takeshi嘗試一步一步地來引導大家,如何從ER-Model轉換成Relational Model
25~28頁,是一個貼近實務的案例,此案例是一個線上書店系統的類別圖(Class Diagram)(也是takeshi論文的一部分啦:p),其中有複雜的繼承和樹狀遞迴的概念,takeshi使用JPA(Java Persistence API),來把它們轉換成Relational Model
希望對有興趣的朋友有點幫助囉 ^^
2012年2月12日 星期日
雲端資料庫之設計與實作
這陣子takeshi在公司幫忙作雲端相關的案子,也應長官的要求在年前跟同事報告了相關資訊,所以takeshi作了以下ppt檔,放在這跟大家分享囉~
關於21頁的demo,是takeshi使用了VM Player作成的兩個節點,用來跟同事們demo如何使用hadoop和HBase,安裝規格如下...
VM跑的Linux版本是:Fedora-15(不過官方已升級到16了啦...)
Hadoop版本:hadoop-0.20.203.0,安裝資訊在這裡
HBase版本:hbase-0.90.4,安裝資訊在這裡
關於24頁的demo,是takeshi使用最近opensource的專案JackHare,來操作HBase;因為JackHare目的是一個遵守JDBC 4.0規範的實作(目前支援HBase-0.90.4),所以takeshi是在同事面前demo了這些操作;關於JackHare的安裝步驟在這裡,有興趣的朋友可以試試看ㄛ ^^
最近takeshi在跟雲端"交朋友"的過程 ,也獲得了一些經驗,之後再跟朋友們分享囉 ^^
關於21頁的demo,是takeshi使用了VM Player作成的兩個節點,用來跟同事們demo如何使用hadoop和HBase,安裝規格如下...
VM跑的Linux版本是:Fedora-15(不過官方已升級到16了啦...)
Hadoop版本:hadoop-0.20.203.0,安裝資訊在這裡
HBase版本:hbase-0.90.4,安裝資訊在這裡
關於24頁的demo,是takeshi使用最近opensource的專案JackHare,來操作HBase;因為JackHare目的是一個遵守JDBC 4.0規範的實作(目前支援HBase-0.90.4),所以takeshi是在同事面前demo了這些操作;關於JackHare的安裝步驟在這裡,有興趣的朋友可以試試看ㄛ ^^
最近takeshi在跟雲端"交朋友"的過程 ,也獲得了一些經驗,之後再跟朋友們分享囉 ^^
2012年1月28日 星期六
軟體專案的素質之二 ─ 整體設計之 系統設計篇
由於takeshi本身是developer出身,自認為自己對這一塊領域和其他領域相比(專案管理和自動化工具)應該要來的更得心應手一點吧,同樣地takeshi再把心智圖放在底下供大家參考囉~
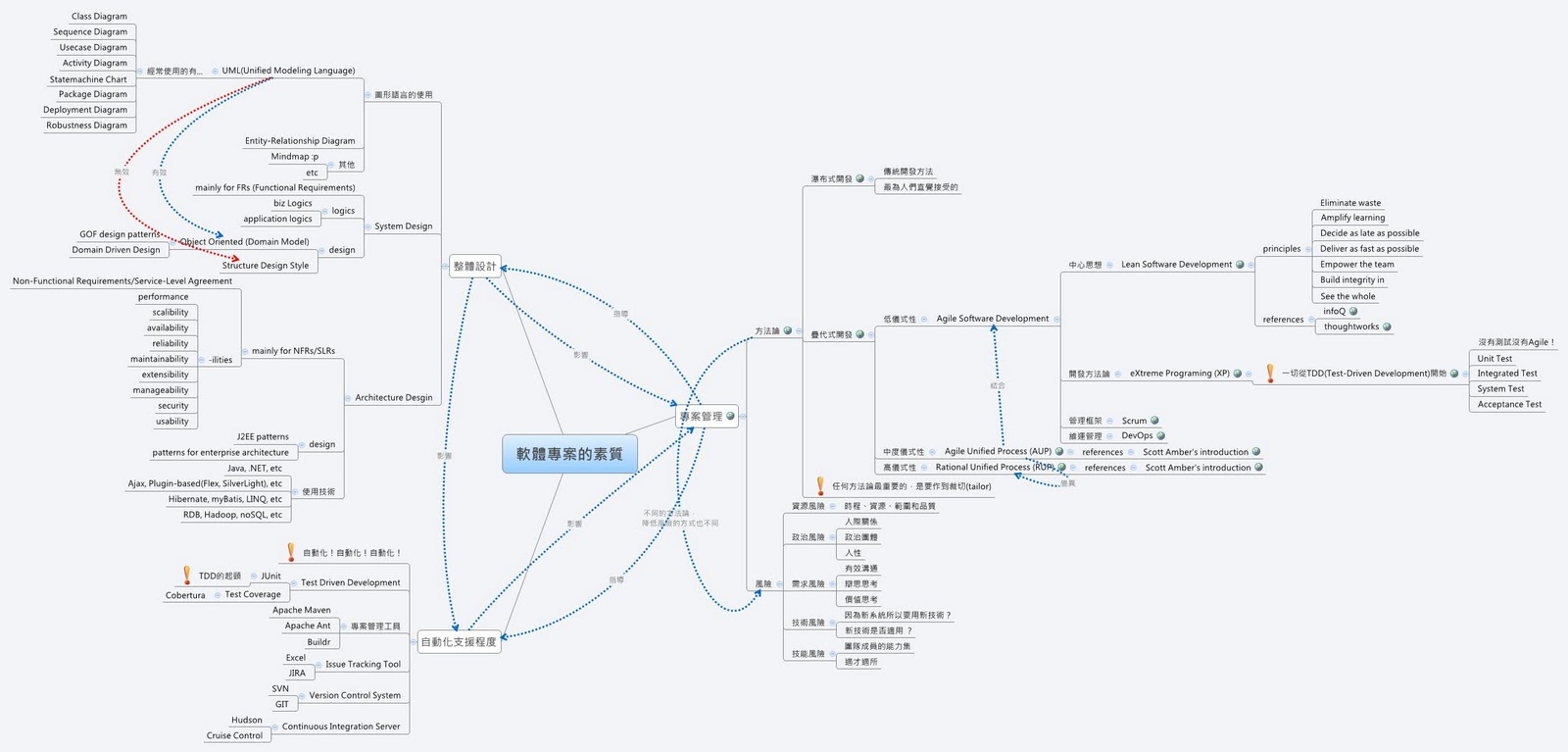 |
| 軟體專案的素質,本blog整理 |
如果朋友們有其它想法或意見,takeshi歡迎大家的意見ㄛ~
就takeshi理解,Kenming在文章中提及,軟體系統開發應該由需求觀點開始,向user蒐集功能性和非功能性需求;然後再把蒐集到的需求帶進結構觀點,該觀點主要是處理系統的功能性需求,對問題領域(Problem Domain)作分析以導出領域模型(Domain Model);接著再進入實作觀點,該觀點主要是處理非功能性需求,考慮使用什麼樣的架構、平台或技術來支援領域模型的運作。
takeshi要提醒三點
1. 以上這三個主要步驟是使用覆往式(Iterative & Incremental)開發來進行的,一次覆往(Iteration),針對當下蒐集欲實作之需求(usecase)為主,走到下一個覆往,再慢慢重構(Refactoring)。
2.需求價值高(對user)和技術難度高(對開發團隊)的需求先作,這樣一來,專案走到越後面,會越穩定,可參考RUP的Elaboration和Construction之介紹。
3. 不要忘記專案管理和自動化測試與相關工具的支援ㄛ!
然而,takeshi自己在實務上的經驗,發現到很多開發團隊所採取的步驟如下
 | |
| takeshi在實務上的觀察,本blog整理 |
由上圖可看出,這些開發團隊收到需求之後(需求觀點),立刻就開始決定技術平台和設計等,並開始實作(實作觀點),完全忽略了領域模型的存在(結構觀點),這樣的軟體開發步驟,會導致最終產出的系統缺乏彈性,以至於少許的需求變動就讓系統面臨大改的窘境;而系統不斷的面臨大改,導致系統的整體設計概念崩潰,而讓系統最終走入惡性循環的命運。
所以結構性觀點到底是什麼呢?takeshi認為結構性觀點其實是物件導向系統開發的核心,也就是領域模型(Domain Model),那領域模型到底是啥東東呢?takeshi可能要先稍微介紹一下程式語言的歷史演進,再跟大家說明到底啥是領域模型。
程式語言的演進簡史
從程式語言開始發展的1950年早期,到目前為止,軟體系統的開發方向是往越來越高階的抽象化層次
- 機器語言(Machine Language)
- 組合語言(Assembly Language)
- 高階程式語言(High Level Programming Language)
- 結構式語言(Structured Programming)
- 物件導向語言(Object-Oriented Programming)
由上簡史可看出,我們常說物件導向語言的特性就是封裝、繼承和多型,而它跟結構式語言之間的分野,最大的不同,就是可以幫助系統開發團隊可以使用一個更直覺、更有彈性的方式來開發系統,讓相關人員可以更聚焦在領域問題上!
有關於系統設計方面,近年主要採用的兩種設計風格如下
Transaction Script設計風格
Martin Fowler的定義如下
Organize business logic by procedures where each procedure handles a single request from presentation.
| Transaction Script設計風格,本blog整理 |
簡言之,就是SD依照SA開出的需求規格,重頭到尾地把相關設計與開發實作出來,然而這樣的設計風格,會不自覺地使得系統的架構與商業邏輯之程式碼綁在一個或多個需求上,如上圖所示,系統的每一個tier都綁在由需求延伸出來的紅線上,然而end user的需求是一天到晚都在變動的(I know it when I see it),所以Transaction Script設計風格的系統架構很容易就會因需求變動發生大範圍的影響,使得接受需求變動的彈性較低。
Domain Model設計風格
依Martin Fowler的定義如下
An object model of the domain that incorporates both behavior and data.
 |
| Domain Model設計風格,本blog整理 |
此設計風格主要是強調在開發系統時,除了user的需求之外,其實我們還要更關注user所在的商業環境!因為user會提出需求,其背後是因為商業環境的驅動使然,所以系統除了要提供滿足user需求的服務之外,其核心應該建立在user背後的商業環境上,因為其和需求本身相較,是本質上穩定不變的部分。如此,即使user的需求天天在變,系統受到影響的部分將會有效減少,因為user的商業環境並不是天天在變動的。然而此種設計風格是需要SA大力支持的,因為需要有人作商業塑模,所以SA對於軟體工程的認知和系統抽象化思考是此設計風格事觀重要的一環。
此外,Martin Fowler也在『Patterns of enterprise application architecture』 一書中,提出了他對Stransaction風格和Domain Model風格的適用範圍,如下圖(質化,非量化)...
| 不同設計風格在不同系統複雜度之下所花費的心力比較圖,Patterns of enterprise application architecture |
一般的作法是,當系統規模較小、商業邏輯相對簡單時,首先可以考慮先使用Stransaction style,來快速產出可運作系統(因為它初期所要花費的心力最小),但當系統欲處理之商業邏輯慢慢演變得越來越複雜、規模也越來越大時,takeshi建議趕快把系統重構成Domain Model style,來取得 面對複雜需求,仍然可以有效降低花費心力和提成系統彈性的能力。
如何使用Domain Model設計風格
Domain Model設計風格是目前takeshi在作系統設計的主力,所以本文章之後都聚焦在Domain Model上來作討論;另一方面,takeshi認為,Transaction style在實務上到處可見,有想要繼續討論的朋友可以跟takeshi說ㄛ~
Domain Driven Design
Domain Model設計風格是一種概念,換言之,可以實踐它的方式著實不少,takeshi目前實踐Domain Model的方式是遵照著Domain Driven Design社群的建議來作為設計的指導原則,有興趣的朋友們也可以參考此社群提供的功能完整的sample project(也有.NET版本的ㄛ);這個社群網站最初是起源於對一本書的讀書會,這本書就是『Domain-Driven Design: Tackling Complexity in the Heart of Software』,takeshi認為,此書是想要跨入Domain Model設計領域的朋友們,一定要讀的一本著作ㄛ,強力推薦~
FOG Design Pattern
這是欲加強自身功力的developer的必讀著作『Design Patterns: Elements of Reusable Object-Oriented Software』,這本書是討論design pattern的第一本書(1994年出版),也是作者的論文,所以有很多不易咀嚼的文章段落和少見的程式範例(Small Talk和C++),現今已有很多很友善的書籍來針對design pattern作討論,像takeshi的第一本design pattern的書是『Head First Design Patterns』,真的有好懂很多,強力推薦給有興趣的朋友們~
另外takeshi要再跟朋友們分享的是,takeshi在一開始學習design pattern時,一直找不到機會使用它們,過程中也和許多developer討論過,有些developer的論點是:「design pattern只是一種理論,實務上很難作發揮」,但經過takeshi多年下來的驗證 ,發現這完全是因為設計風格的問題!我們學了design pattern但使用不上的原因,完全是因為我們採取的是Transaction風格的關係,一旦我們採用了Domain Model風格,design pattern你想不用都難!
實務經驗分享
takeshi使用Domain Model設計風格來實作專案大約經歷了兩個寒暑,其中也專案上線後由其他Developer接手維護的例子(當時takeshi已離開此工作環境了),當初takeshi在使用Domain Model設計風格來實作專案,希望能達到以下三點效益
1. 系統能有一個整體設計概念(核心)
在Domain Driven Design中提出,一個基於Domain Model作出的系統設計,會成為Ubiquitous Language,它記錄著此系統的核心概念;takeshi認為只要後手developer能搞懂這個由Domain Model組成的類別圖(當然還是要搭配循序圖和code),後手developer應該很快地就能搞懂此系統的商業邏輯全貌。
2.彈性大、擴充能力佳
由於系統提供的服務,是基於Domain Model之物件互動所產生的,一旦需求有變動,後手developer只要重新搭配物件互動的流程,即可完成變動之需求,系統彈性大 ;如果是新的需求, 後手developer也可以在domain model的整個繼承樹裡,找出變異的方法,透過繼承和多型的手段,來快速提供新的行為,而不須更動原本已撰寫好的物件互動流程,系統擴充能力佳。
3. 系統邏輯與使用者介面(User Interface,UI)完全隔離
由於系統的商業邏輯是基於Domain Model及其產生物件之互動所完成,所以跟系統的UI是完全沒有關係的(有效隔離);一旦End User要求變動UI,後手developer在更改UI時,完全不會影響到系統商業邏輯;如果是需要在UI上增加新的欄位,通常該欄位值也是Domain Model類別的特定屬性(Property)(也就是封裝),所以對後端系統商業邏輯也不會有大的影響(甚至沒有影響)。
而實際上,當後手developer在接手takeshi的專案時,的確要經過一段陣痛期(期間長度因人而異),因為從原本的Transaction設計風格要轉換到Domain Model設計風格,是一種思想轉換(paradigm shift),當通過陣痛期之後,經takeshi跟這位後手developer的確認,的確達到了takeshi一開始希望產生的效益!但對於沒有通過陣痛期的developer來說,他們大概會說:「這是什麼鬼東西,這種程式到底是怎麼寫出來的啊!」,對這些developer,takeshi也只能說:「你們的固執己見,有可能讓你們自己喪失了一個發現軟體開發新視界的機會ㄚ」。
2012年1月3日 星期二
軟體專案的素質之一 ─ 專案管理
有時候takeshi會跟同事們討論,軟體專案天生擁有這麼多複雜的特性,像是客戶需求不停地變動、新技術不停出現、系統效能不彰、外在環境變動(市場波動或政治因素等)、內在環境變動(資源不足或溝通障礙等)等...,在這些複雜的因素之下,我們到底要怎麼判斷一個軟體專案的體質優劣呢?
關於這點,雖然 takeshi也只是新手PM,有很多東東要學習,但是仍有一些個人的想法可以跟各位朋友們分享(沒看過豬走路,也吃過豬肉ㄚ),takeshi認為至少可以從三點來判斷軟體專案的素質,那就是專案管理、整體設計和自動化支援程度!
takeshi雖然嘴巴上講了粉多次,但還沒把它們好好地寫下來過,為了可以讓takeshi自己可以好好整理這些概念,takeshi就這三個概唸作出發,畫出了以下心智圖,心智圖檔案在這裡

由心智圖可看出,這三個概念其實是由很多子概念組成的,這每個子概念至少都可以多讀個好幾本書說>"<, takeshi也不是全都懂,或是全使用過,不過察覺是智慧的開端,takeshi"儘量"就每個概唸作簡單的介紹,並附上相關連結,讓有興趣的朋友們去深入瞭解~
但礙於要提及的東東粉多,所以takeshi打算拆成多個文章來介紹它們,這次就先從專案管理說起,其他的部分就請各位朋友們耐心期待一下嚕~
專案管理
說到專案管理,是每個人都掛在嘴上的東東,它的定義是指「一個暫時性(temporary)的組織與努力付出,在一段事先確認的時間內,運用事先決定的資源,以產出一個獨特的(unique)且可以事先定義的產品、服務或結果。」,就此定義來說,每個人多少都有專案管理的經驗了,只是範圍和目的的不同罷了,買房子是一種專案管理,結婚也是一種專案管理,甚至生小孩也是一個偉大的專案管理工作ㄚ!當然我們這邊主要是針對 軟體開發 作討論啦 :p
方法論
定義為「在軟體工程與專案管理中,方法學通常是指一系列編撰好的建議方法,有時還包括訓練材料、正規教育性程序、工作表和圖像工具。與其被稱為方法學,這些概念比較適合叫作方法」;雖然以工程角度來看,軟體開發是一項非常年輕的學門,但已有許多專家學者提出了非常多的方法論,來解決軟體開發中各項活動所遇到的各種問題。takeshi只就常見的 瀑布式開發 和近年非常容易聽到的 疊代式開發 作介紹~
瀑布式開發
定義為「開發被認為是按照需求分析,設計,實現,測試 (確認), 集成,和維護堅定地順暢地進行」,其實也就是依循著系統開發生命週期(SDLC, System LifeCycle)的順序,一步一步的往下走;其定義背後其實有一種假設,那就是使用者需求變動很少,所以該模型假設因需求變動而回到上一步驟的頻率很低,而且每次回到上一步的風險是很大的,例如在測試階段使用者發現系統效能不符合預期,故要求改善,然而因系統架構已然定型,故最後為了要克服系統效能不彰的缺陷,必須冒著更改架構的高風險來達成。
然而在實務上takeshi接觸到的專案,幾乎都是以此概念在進行的,即使是他們表面上打著疊代式開發的招牌...
疊代式開發
定義為「整個開發工作被組織為一系列的短小的、固定長度(通常兩到四週)的小項目,被稱為一系列的疊代。每一次疊代都包括了需求分析、設計、實現與測試。採用這種方法,開發工作可以在需求被完整地確定之前啟動,並在一次疊代中完成系統的一部分功能或業務邏輯的開發工作。再通過客戶的反饋來細化需求,並開始新一輪的疊代」;在以上這麼冗長的定義來看,takeshi覺得最重要的概念是提早把風險暴露出來,在每一個疊代要被release之前,一定要讓系統的終端使用者確認和使用,讓他們越早把問題和需求變更反饋給開發團隊,調整的功夫就越小;takeshi認為這是疊代式開發最具有價值的環節之一,然而在上一節提到,許多表面上打著疊代式開發招牌的團隊,通常是開發的確切了多個疊代,但往往卻在最後系統上線之前的UAT(User Acceptance Test),才讓終端使用者上測試環境測試,導致在最後一刻爆出許多問題需要處理,在此時花費的成本是最大的...
以下秀出一個defect在系統不同的生命週期所要花費的成本比較圖 (美元計),供大家參考

敏捷式開發方法 (Agile Software Development)
敏捷式開發方法是近年來相當火紅的軟體開發概念,他的中心思想是Lean Software Development(精益軟體開發思想,takeshi不太想用中文講它啦...),源自於日本豐田汽車公司的製造概念Lean Manufacturing(同時他們也是Just In Time的創造者),其重點就是要組織全面消除浪費;而在軟體開發領域來說,軟體的交付對於客戶公司的管理階層來說,其實是一種端對端的概念,也就是說「我付了一筆錢,等一段時間,就有一個軟體自動化系統可以使用」,而Lean就是針對這端到端之間的所有流程,都要把浪費降到最低;而所謂的浪費是指「任何不能為客戶增加價值的行為即是浪費」;敏捷式開發即是把其思想當作核心,演變出了相對應的方法論,來幫助軟體專案流程。
此外,敏捷式開發方法也被稱為是「低儀式性」的,就是它跟傳統的開發方法比較起來,在系統開發週期中的每個階段所要求的產出文件,要少了很多,一般的敏捷式開發方法通常到專案結束的產出只有 需求文件(user stories)、自動化測試程式和滿足客戶需求的可運行系統。通常少於20人的團隊較適合敏捷式開發,不過takeshi認為還是要看當下環境怎麼去做配合啦。
現今的敏捷式開發方法,可謂是百家爭鳴,就takeshi的理解,目前的主流可分為三個部分...
指導管理階層如何使用敏捷式管理。
指導如何把開發團隊跟維運團隊緊密結合。
以上列出的這三個不論是要稱它們為框架、方法論或概念也好,反正它們就是分別從不同的角度 管理、開發和維運來切入,幫助其中參與之相關角色來採用敏捷式開發。takeshi對這三個東東雖然寫得少,但它們是粉重要的ㄛ,只是這三個東東可以寫得粉長,而網路上已經有很多優秀的資源可供參考了,takeshi有機會再跟大家討論唄~
關於敏捷式開發有一個非常重要的觀念是大家不可不知的,那就是一定要採用 TDD(Test Driven Development) !(自動化、可回歸的測試程式貫穿整個單元、整合、系統測試)因為當測試程式的涵蓋率夠高的時候,它會形成一張品質的安全網,成為整個專案的重要基石,敏捷式開發之中提到的每個疊代都要release可用的系統、不停重構、提早暴露風險,etc,都是建構在自動化測試之上的ㄛ!通常這時候就會有人問說,到底測試程式要寫多少才足夠呢?Martin Fowler的回答是「至少要跟專案程式碼差不多多吧!」
Rational Unified Process (RUP)
目前由IBM公司在維護和推廣此方法論,RUP也是疊代式開發的一種類型,但它跟敏捷式開發比較起來,就好像是在光譜的兩個極端(也就是高儀式性),它要求在其定義的管理活動的每個階段,都需要產出或修改相關文件,所以相關人員需花費許多時間來作維護。所以RUP通常適合多於20人以上的大型專案。撇開專案文件的要求不說,takeshi是相當喜歡此方法論的概念^^
Agile Unified Process (AUP)
剛剛提到Agile Software Development和RUP就像是兩個極端對立的世界,而Scott Amber提出了敏捷化(agilize)的RUP版本 AUP,它介於Agile和RUP之間,既顧及了在RUP規範中要求的必要文件產出,在其他部分則是採用了Agile的活動,如TDD、AMDD (Agile Modeling Driven Development)、Agile Change Management和DataBase Refactoring等,使得開發團隊又多了一個新的選擇;以takeshi的看法,在台灣面向客戶的專案,採用Agile可能執行面有困難(公司內部的專案可行性可能比較高),因為通常客戶還是會要求要有專案相關文件(需求文件、設計文件、測試計畫、佈署計畫,etc),而RUP是太重量級了,所以AUP可能不失為是個好的選擇ㄛ~
裁切(Tailor)
takeshi要提醒一下,這世上所有的軟體開發方法論,都要求使用者在使用時,要配合當下環境作適度的裁切,而不是一味的照單全收,到最後通常會落得消化不良的下場ㄛ
風險
以上takeshi所提到的軟體開發的方法論,其主要用意都是一樣的,就是如何規避風險,來產出user滿意且品質良好的軟體系統,只是採取的工具與方法不同罷了(有些是強調文件的完整性,有些是強調產出隨時可運行的系統);所以我們也要來瞭解一下這些"風險"到底有哪些呢?takeshi曾經上過的OO-226課程,把風險作了以下五種分類
所以專案團隊在選擇開發方法論的時候,要考量此方法論是不是真的能解決或降低當下環境的風險,確定了方法論後,再依需求對方法論作裁切動作,試著run兩、三個疊代,再慢慢的調整方法論的細節,到整個方法論跟開發團隊非常契合為止~
專案管理 與 整體設計和自動化支援程度 的關係
從專案管理開始,決定採用哪種開發方法論,間接指定了採取哪一種 整體設計概念 和 自動化工具的支援程度;而決定了以上兩者,在專案實際開始執行時,又會回過頭來影響的專案管理的部分,而良性的影響,會漸漸成為良性循環,反之亦然。
takeshi在台灣實務上的經驗是,為數不少的清況下,專案成員不知道自己的專案是在run哪種方法論 或是把覆往式run成瀑布式 亦或是 壓根沒聽過上述提到的東東...,但takeshi認為這是影響專案優劣的重要起點,不可不慎ㄚ...
關於這點,雖然 takeshi也只是新手PM,有很多東東要學習,但是仍有一些個人的想法可以跟各位朋友們分享(沒看過豬走路,也吃過豬肉ㄚ),takeshi認為至少可以從三點來判斷軟體專案的素質,那就是專案管理、整體設計和自動化支援程度!
takeshi雖然嘴巴上講了粉多次,但還沒把它們好好地寫下來過,為了可以讓takeshi自己可以好好整理這些概念,takeshi就這三個概唸作出發,畫出了以下心智圖,心智圖檔案在這裡

由心智圖可看出,這三個概念其實是由很多子概念組成的,這每個子概念至少都可以多讀個好幾本書說>"<, takeshi也不是全都懂,或是全使用過,不過察覺是智慧的開端,takeshi"儘量"就每個概唸作簡單的介紹,並附上相關連結,讓有興趣的朋友們去深入瞭解~
但礙於要提及的東東粉多,所以takeshi打算拆成多個文章來介紹它們,這次就先從專案管理說起,其他的部分就請各位朋友們耐心期待一下嚕~
專案管理
說到專案管理,是每個人都掛在嘴上的東東,它的定義是指「一個暫時性(temporary)的組織與努力付出,在一段事先確認的時間內,運用事先決定的資源,以產出一個獨特的(unique)且可以事先定義的產品、服務或結果。」,就此定義來說,每個人多少都有專案管理的經驗了,只是範圍和目的的不同罷了,買房子是一種專案管理,結婚也是一種專案管理,甚至生小孩也是一個偉大的專案管理工作ㄚ!當然我們這邊主要是針對 軟體開發 作討論啦 :p
方法論
定義為「在軟體工程與專案管理中,方法學通常是指一系列編撰好的建議方法,有時還包括訓練材料、正規教育性程序、工作表和圖像工具。與其被稱為方法學,這些概念比較適合叫作方法」;雖然以工程角度來看,軟體開發是一項非常年輕的學門,但已有許多專家學者提出了非常多的方法論,來解決軟體開發中各項活動所遇到的各種問題。takeshi只就常見的 瀑布式開發 和近年非常容易聽到的 疊代式開發 作介紹~
瀑布式開發
定義為「開發被認為是按照需求分析,設計,實現,測試 (確認), 集成,和維護堅定地順暢地進行」,其實也就是依循著系統開發生命週期(SDLC, System LifeCycle)的順序,一步一步的往下走;其定義背後其實有一種假設,那就是使用者需求變動很少,所以該模型假設因需求變動而回到上一步驟的頻率很低,而且每次回到上一步的風險是很大的,例如在測試階段使用者發現系統效能不符合預期,故要求改善,然而因系統架構已然定型,故最後為了要克服系統效能不彰的缺陷,必須冒著更改架構的高風險來達成。
然而在實務上takeshi接觸到的專案,幾乎都是以此概念在進行的,即使是他們表面上打著疊代式開發的招牌...
疊代式開發
定義為「整個開發工作被組織為一系列的短小的、固定長度(通常兩到四週)的小項目,被稱為一系列的疊代。每一次疊代都包括了需求分析、設計、實現與測試。採用這種方法,開發工作可以在需求被完整地確定之前啟動,並在一次疊代中完成系統的一部分功能或業務邏輯的開發工作。再通過客戶的反饋來細化需求,並開始新一輪的疊代」;在以上這麼冗長的定義來看,takeshi覺得最重要的概念是提早把風險暴露出來,在每一個疊代要被release之前,一定要讓系統的終端使用者確認和使用,讓他們越早把問題和需求變更反饋給開發團隊,調整的功夫就越小;takeshi認為這是疊代式開發最具有價值的環節之一,然而在上一節提到,許多表面上打著疊代式開發招牌的團隊,通常是開發的確切了多個疊代,但往往卻在最後系統上線之前的UAT(User Acceptance Test),才讓終端使用者上測試環境測試,導致在最後一刻爆出許多問題需要處理,在此時花費的成本是最大的...
以下秀出一個defect在系統不同的生命週期所要花費的成本比較圖 (美元計),供大家參考

參考網站在這裡
敏捷式開發方法 (Agile Software Development)
敏捷式開發方法是近年來相當火紅的軟體開發概念,他的中心思想是Lean Software Development(精益軟體開發思想,takeshi不太想用中文講它啦...),源自於日本豐田汽車公司的製造概念Lean Manufacturing(同時他們也是Just In Time的創造者),其重點就是要組織全面消除浪費;而在軟體開發領域來說,軟體的交付對於客戶公司的管理階層來說,其實是一種端對端的概念,也就是說「我付了一筆錢,等一段時間,就有一個軟體自動化系統可以使用」,而Lean就是針對這端到端之間的所有流程,都要把浪費降到最低;而所謂的浪費是指「任何不能為客戶增加價值的行為即是浪費」;敏捷式開發即是把其思想當作核心,演變出了相對應的方法論,來幫助軟體專案流程。
此外,敏捷式開發方法也被稱為是「低儀式性」的,就是它跟傳統的開發方法比較起來,在系統開發週期中的每個階段所要求的產出文件,要少了很多,一般的敏捷式開發方法通常到專案結束的產出只有 需求文件(user stories)、自動化測試程式和滿足客戶需求的可運行系統。通常少於20人的團隊較適合敏捷式開發,不過takeshi認為還是要看當下環境怎麼去做配合啦。
現今的敏捷式開發方法,可謂是百家爭鳴,就takeshi的理解,目前的主流可分為三個部分...
指導管理階層如何使用敏捷式管理。
- eXtreme Programing (XP)
指導如何把開發團隊跟維運團隊緊密結合。
以上列出的這三個不論是要稱它們為框架、方法論或概念也好,反正它們就是分別從不同的角度 管理、開發和維運來切入,幫助其中參與之相關角色來採用敏捷式開發。takeshi對這三個東東雖然寫得少,但它們是粉重要的ㄛ,只是這三個東東可以寫得粉長,而網路上已經有很多優秀的資源可供參考了,takeshi有機會再跟大家討論唄~
關於敏捷式開發有一個非常重要的觀念是大家不可不知的,那就是一定要採用 TDD(Test Driven Development) !(自動化、可回歸的測試程式貫穿整個單元、整合、系統測試)因為當測試程式的涵蓋率夠高的時候,它會形成一張品質的安全網,成為整個專案的重要基石,敏捷式開發之中提到的每個疊代都要release可用的系統、不停重構、提早暴露風險,etc,都是建構在自動化測試之上的ㄛ!通常這時候就會有人問說,到底測試程式要寫多少才足夠呢?Martin Fowler的回答是「至少要跟專案程式碼差不多多吧!」
Rational Unified Process (RUP)
目前由IBM公司在維護和推廣此方法論,RUP也是疊代式開發的一種類型,但它跟敏捷式開發比較起來,就好像是在光譜的兩個極端(也就是高儀式性),它要求在其定義的管理活動的每個階段,都需要產出或修改相關文件,所以相關人員需花費許多時間來作維護。所以RUP通常適合多於20人以上的大型專案。撇開專案文件的要求不說,takeshi是相當喜歡此方法論的概念^^
Agile Unified Process (AUP)
剛剛提到Agile Software Development和RUP就像是兩個極端對立的世界,而Scott Amber提出了敏捷化(agilize)的RUP版本 AUP,它介於Agile和RUP之間,既顧及了在RUP規範中要求的必要文件產出,在其他部分則是採用了Agile的活動,如TDD、AMDD (Agile Modeling Driven Development)、Agile Change Management和DataBase Refactoring等,使得開發團隊又多了一個新的選擇;以takeshi的看法,在台灣面向客戶的專案,採用Agile可能執行面有困難(公司內部的專案可行性可能比較高),因為通常客戶還是會要求要有專案相關文件(需求文件、設計文件、測試計畫、佈署計畫,etc),而RUP是太重量級了,所以AUP可能不失為是個好的選擇ㄛ~
裁切(Tailor)
takeshi要提醒一下,這世上所有的軟體開發方法論,都要求使用者在使用時,要配合當下環境作適度的裁切,而不是一味的照單全收,到最後通常會落得消化不良的下場ㄛ
風險
以上takeshi所提到的軟體開發的方法論,其主要用意都是一樣的,就是如何規避風險,來產出user滿意且品質良好的軟體系統,只是採取的工具與方法不同罷了(有些是強調文件的完整性,有些是強調產出隨時可運行的系統);所以我們也要來瞭解一下這些"風險"到底有哪些呢?takeshi曾經上過的OO-226課程,把風險作了以下五種分類
- 政治風險
- 需求風險
- 資源風險
- 技術風險
- 技能風險
所以專案團隊在選擇開發方法論的時候,要考量此方法論是不是真的能解決或降低當下環境的風險,確定了方法論後,再依需求對方法論作裁切動作,試著run兩、三個疊代,再慢慢的調整方法論的細節,到整個方法論跟開發團隊非常契合為止~
專案管理 與 整體設計和自動化支援程度 的關係
從專案管理開始,決定採用哪種開發方法論,間接指定了採取哪一種 整體設計概念 和 自動化工具的支援程度;而決定了以上兩者,在專案實際開始執行時,又會回過頭來影響的專案管理的部分,而良性的影響,會漸漸成為良性循環,反之亦然。
takeshi在台灣實務上的經驗是,為數不少的清況下,專案成員不知道自己的專案是在run哪種方法論 或是把覆往式run成瀑布式 亦或是 壓根沒聽過上述提到的東東...,但takeshi認為這是影響專案優劣的重要起點,不可不慎ㄚ...
訂閱:
文章 (Atom)